#爬取Python教程博客并转成PDF
今天我们爬取一下python教程博客并把爬取内容转换成PDF储存到本地。
用到的工具
requests
BeautifulSoup
time
pdfkit
wkhtmltopdf
我们先说一下本次要用到的两个库
- pdfkit 这个是将转换PDF的一个工具库。我们可以指定命令安装一下(前提要安装pip)pip install pdfkit pdfkit 是 wkhtmltopdf 的Python封装包。首先安装好下面的依赖包,接着安装 wkhtmltopdf
- time 这个我们可以用来获取程序执行的时间 time.time()
##安装wkhtmltopdf
windows平台直接去wkhtmltopdf官网下载稳定版本并安装就行了,安装好后要记得配置PATH 环境变量。安装好后我们可以在cmd命令窗口测试一下是否配置成功。 wkhtmltopdf http://www.baidu.com/ D:test.pdf (这里要注意一下网址和pdf名字之间是有个空格的)
##好了,工具准备就绪,我们先分析一下网页
我们先打开廖老师python教程的网址http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
可以看到博客左侧是教程目录,右侧是教程正文。我们的思路是把每个目录对应的正文html保存到本地,然后使用pdfkit转换成pdf
我们先看一下教程正文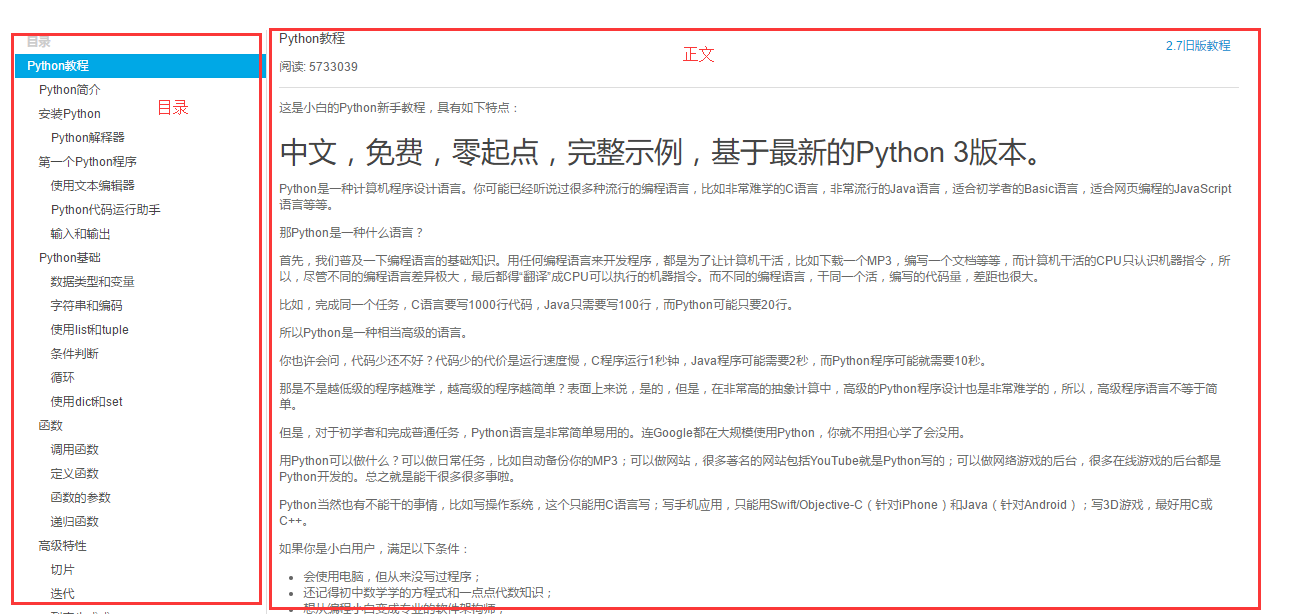
看到下图,我们只需要拿到教程中正文部分就够了,至于那些评论、广告、、是我们不需要的,所以我们先要找到正文对应的标签名字。
我们使用Chrome浏览器自带的工具,选取教程正文,然后我们找到正文对应的标签,这里我们看到标签是x-wiki-content 然后我们就可以开始撸代码了。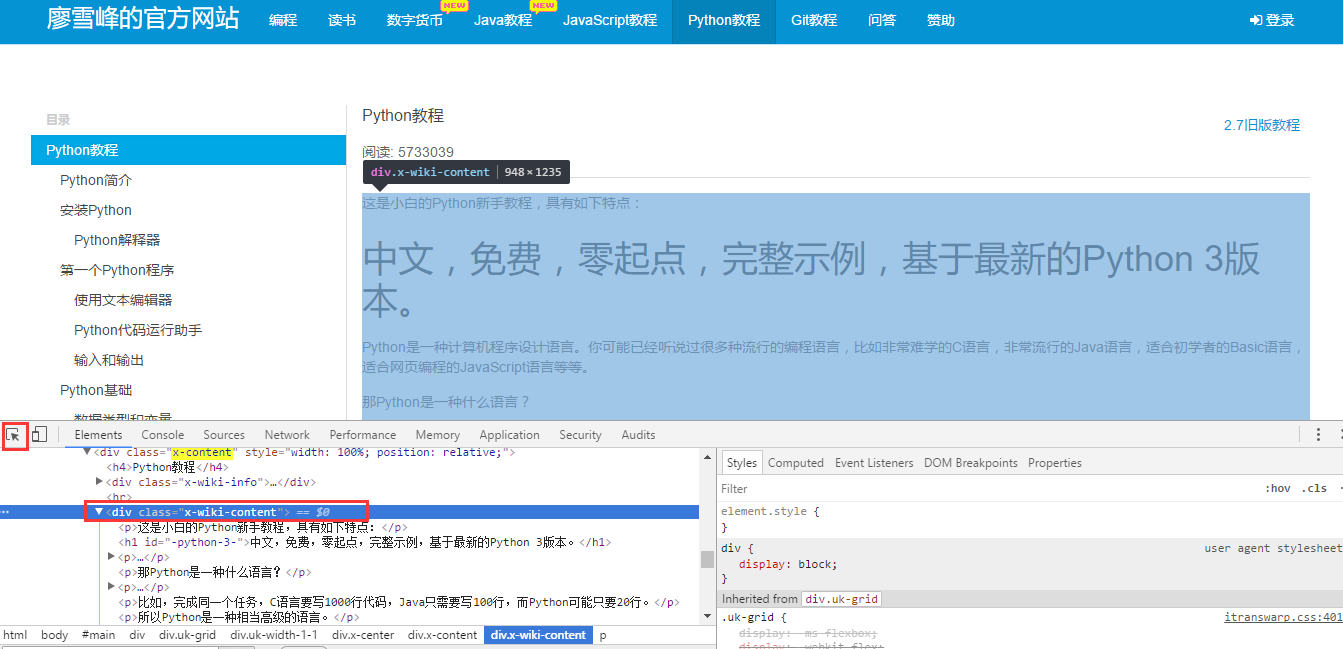
1
2
3
4response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")
注意我们还没有获取正文的标题文字
跟上面相同的方法我们找到正文上面标题文字的对应标签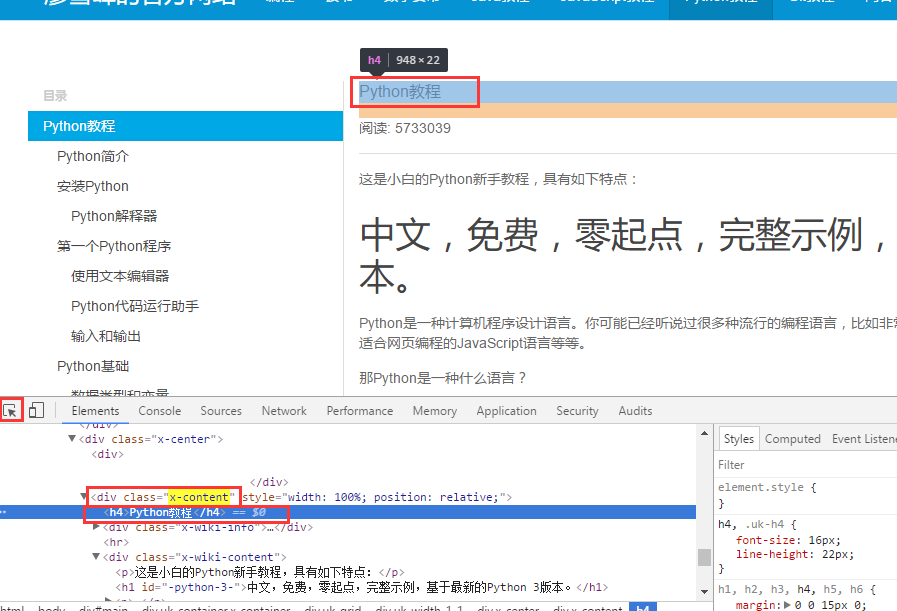
这里我们看到正文对应的标题文字标签是x-content 下的h4标签我们可以使用x-content获取标题,当然也可以使用h4获取,这里我是用的h41
2# 标题
title = soup.find_all('h4')[0].get_text()
然后我们将获取到的正文信息保存到html中,注意原文中的图片使用的相对路径,这样的话我们是访问不到图片的,我们需要改成绝对路径。(有关相对路径和绝对路径不是很清楚的话可以在这里了解一下)相对路径和绝对路径的区别.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15html = h[1:-1]
#print(html)
#body中的img标签的src相对路径的改成绝对路径
pattern = "(<img .*?src=\")(.*?)(\")"
def func(m):
if not m.group(3).startswith("http"):
rtn = m.group(1) + domain + m.group(2) + m.group(3)
return rtn
else:
return m.group(1) + m.group(2) + m.group(3)
html = re.compile(pattern).sub(func, html)
html = html_template.format(content=html)
html = html.encode("utf-8")
with open(name, 'wb') as f:
f.write(html)
##下面我们找出所有目录链接
跟获取正文信息一样,我们要找到目录列表所对应的标签。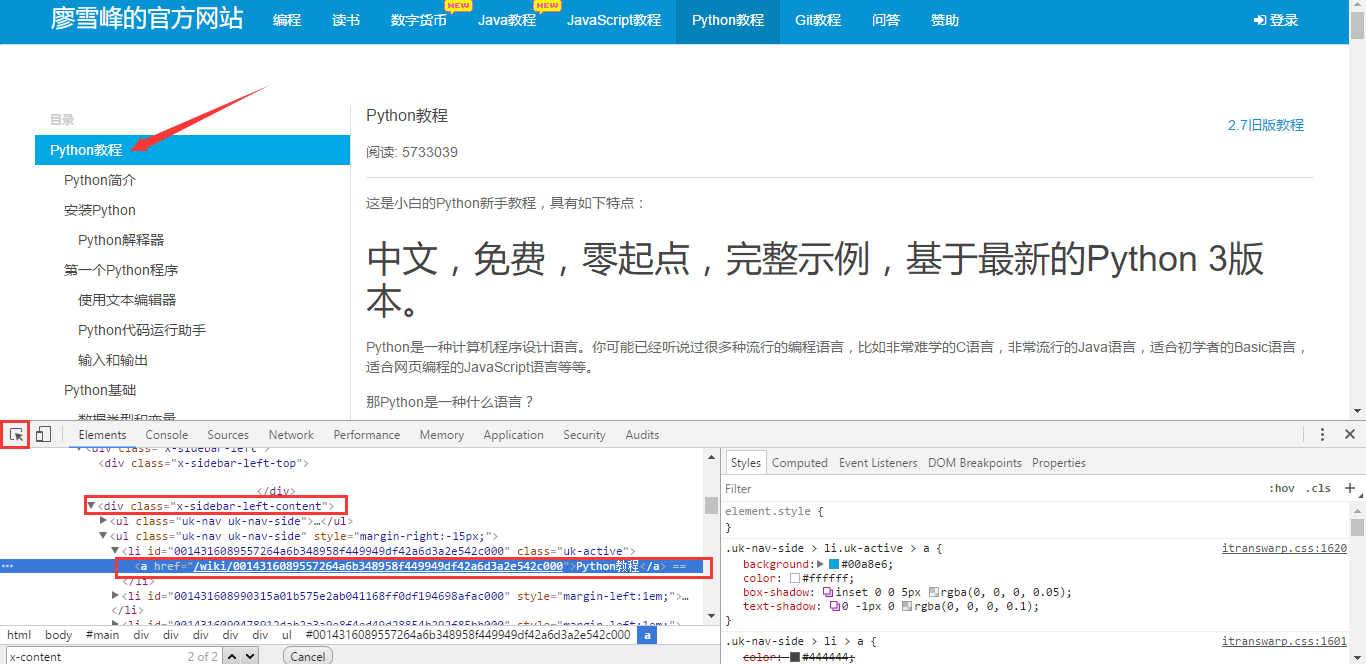
这里目录对应的标签是x-sidebar-left-content 我们获取到目录对应链接是href=”/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000”
这里我们是并不能直接访问的 ,我 们需要处理一下,’href=’肯定是不能要的,所以我们要把这个去掉,然后发现后面这个链接是不全的(对应我们教程的链接)缺少了http://www.liaoxuefeng.com
所以我们要拼接一下路径字符串,处理成正常可以访问的路径
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def get_url_list(url):
last_position = find_last(url, "/") + 1
#print(last_position)
tutorial_url_head = url[0:last_position]
global domain
domain = get_domain(url)
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find(class_="x-sidebar-left-content")
urls = []
#拼接链接地址字符串
for a in menu_tag.find_all('a'):
href = str(a.get('href'))
result = href.find('/')
if result == -1:
url = tutorial_url_head + href
else:
url = domain + href
urls.append(url)
return urls
##最后一步,保存html为PDF
pdfkit提供了很多种选择格式,我们可以根据自己的需要去设置参数。这里就不一一介绍了,有兴趣的好可以去了解一下HTML 转 PDF 之 wkhtmltopdf 工具精讲.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def save_pdf(htmls, file_name):
"""
把所有html文件保存到pdf文件
:param htmls: html文件列表
:param file_name: pdf文件名
:return:
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)
##爬取结果
这篇案例到这里差不多就结束了,我们看一下爬取结果。
##全部代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144# -*- coding=utf-8 -*-
import os
import re
import time
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import pdfkit
import requests
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html>
"""
def get_url_list(url):
last_position = find_last(url, "/") + 1
#print(last_position)
tutorial_url_head = url[0:last_position]
global domain
domain = get_domain(url)
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
menu_tag = soup.find(class_="x-sidebar-left-content")
urls = []
for a in menu_tag.find_all('a'):
href = str(a.get('href'))
result = href.find('/')
if result == -1:
url = tutorial_url_head + href
else:
url = domain + href
urls.append(url)
return urls
def parse_url_to_html(url, name):
"""
解析URL,返回HTML内容
:param url:解析的url
:param name: 保存的html文件名
:return: html
"""
try:
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# 正文
body = soup.find_all(class_="x-wiki-content")
#print(body)
# 标题
title = soup.find_all('h4')[0].get_text()
#print(title)
# 标题加入到正文的最前面,居中显示
center_tag = soup.new_tag("center")
title_tag = soup.new_tag('h1')
title_tag.string = title
center_tag.insert(0, title_tag)
body.insert(0, center_tag)
h = str(body)
html = h[1:-1]
#print(html)
#body中的img标签的src相对路径的改成绝对路径
pattern = "(<img .*?src=\")(.*?)(\")"
def func(m):
if not m.group(3).startswith("http"):
rtn = m.group(1) + domain + m.group(2) + m.group(3)
return rtn
else:
return m.group(1) + m.group(2) + m.group(3)
html = re.compile(pattern).sub(func, html)
html = html_template.format(content=html)
html = html.encode("utf-8")
with open(name, 'wb') as f:
f.write(html)
return name
except Exception as e:
# logging.error("解析错误: " + e, exc_info=True)
print(e)
def save_pdf(htmls, file_name):
"""
把所有html文件保存到pdf文件
:param htmls: html文件列表
:param file_name: pdf文件名
:return:
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)
def find_last(string, char):
last_position = -1
while True:
position = string.find(char, last_position + 1)
if position == -1:
return last_position
last_position = position
def get_domain(url):
r = urlparse(url)
return r.scheme + "://" + r.netloc
#我们要运行的主函数
def main():
print("数据读取中,请稍后...")
url = "http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000"
start = time.time()
#获取url列表
urls = get_url_list(url)
#要保存的pdf名字
file_name = "LXF_python.pdf"
#保存html并拿到列表
htmls = [parse_url_to_html(url, str(index) + ".html") for index , url in enumerate(urls)]
#print(htmls)
#保存到pdf
save_pdf(htmls , file_name)
#删除我们保存到本地的html文件
for html in htmls:
os.remove(html)
total_time = time.time() - start
print("数据读取完毕,总共用时: %f 秒" % total_time)
#设定主函数
if __name__ == '__main__':
main()
好了,就到这里吧,祝大家生活愉快。

