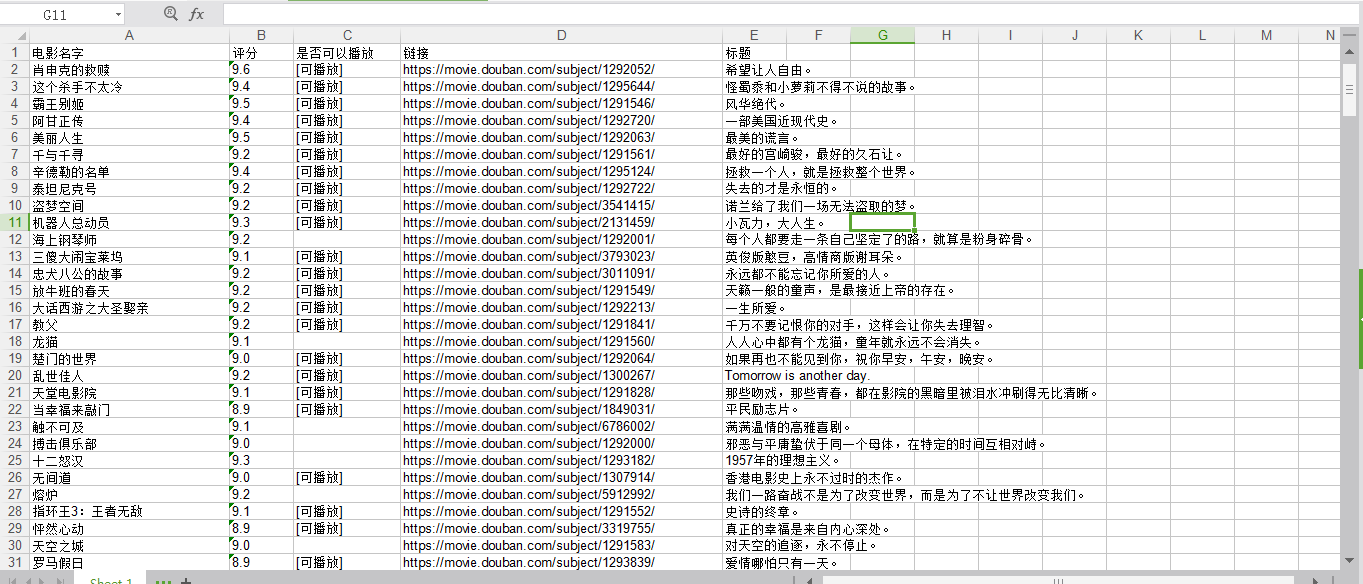
def init_url(): DATA=(('电影名字','评分','是否可以播放','链接','标题'),) for i in range(0,250,25): url = 'https://movie.douban.com/top250?start={}&filter='.format(i) print(url) res = requests.get(url) res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') DATA += get_url_data(soup) create_exl(DATA) def get_url_data(soup): newdata=() for data in soup.select('.info'): if len(data.select('.hd')) > 0: name =data.select('a')[0].text.split(' ')[0].split('\n')[1] pingfen = data.select('.rating_num')[0].text.strip() canplay = '' if len(data.select('.playable')) > 0: canplay = data.select('.playable')[0].text.rstrip() link = data.select('a')[0]['href'] biaoti = '' if len(data.select('.inq')) > 0: biaoti = data.select('.inq')[0].text newdata += ((str(name),str(pingfen),str(canplay),str(link),biaoti),) return newdata def create_exl(DATA): for i,row in enumerate(DATA): for j,col in enumerate(row): booksheet.write(i,j,col) workbook.save('douban_Top250.xls')