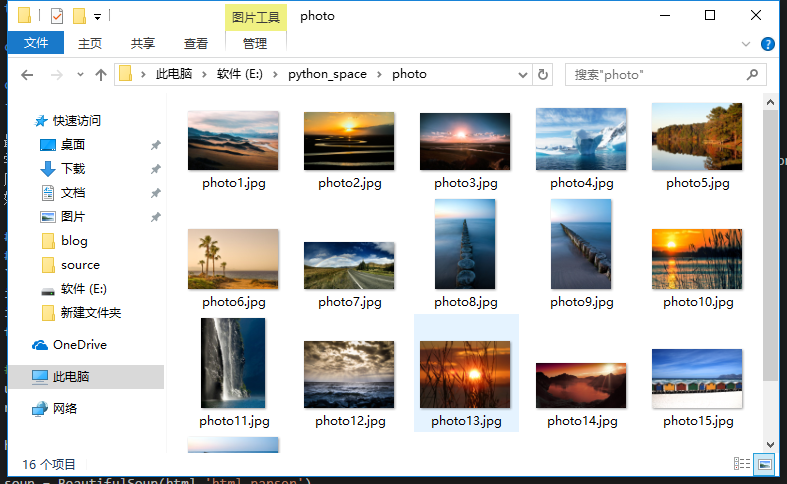
最近在自学python刚学了点语法知识,从下面代码中也能看出来用的不是很合适~
学着别人写了个小爬虫,算是个爬虫吧,就是去固定网站上抓取一些图片,网上有很多教程,这篇文章也是记录一下我用Python写的第一个小爬虫..
好了不多说 上代码(等两天再修一下,现在只能抓取一个页面的图片)
抓取pixabay上的风景图片代码
使用了 BeautifulSoup 这个包 写爬虫很方便 有时间要好好研究研究
这是要爬取的页面
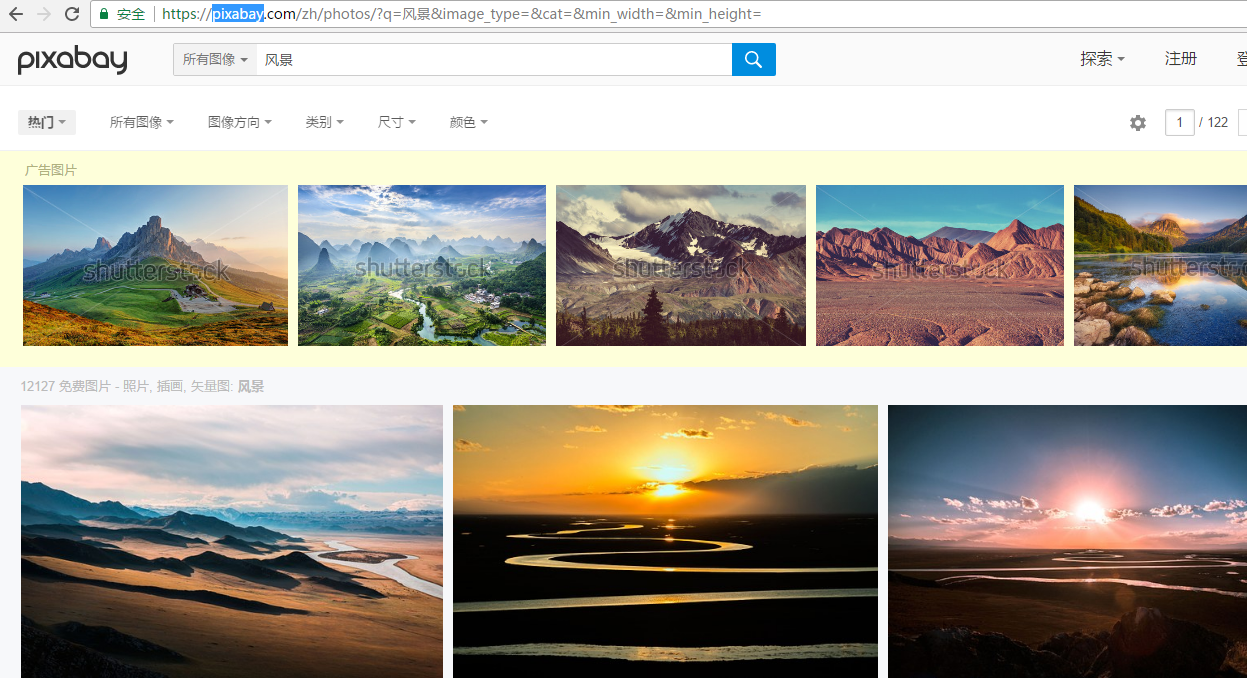
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import urllib.request
import os
from bs4 import BeautifulSoup
#这个是要爬取的网站地址
url = 'https://pixabay.com/zh/photos/?q=%E9%A3%8E%E6%99%AF&image_type=&cat=&min_width=&min_height='
res = urllib.request.urlopen(url)
html = res.read()
soup = BeautifulSoup(html,'html.parser')
#找出所以'img'标签对应的值
result = soup.find_all('img')
links = []
index = 0
for content in result:
#担心下载太多(毕竟是测试)做了一个数量限制(也可以去掉)
if index < 100:
s = content.get('srcset')
if s is None:
ss = s
else:
links.append(s.split(' ')[0])
index+=1
#输出一共找出几个符合的图片地址
print(len(links))
#判断本地是否有photo这个路径,没有的话创建一个
if not os.path.exists('photo'):
os.makedirs('photo')
#循环把图片下载到本地photo路径下
i = 0
for link in links:
i+=1
filename = 'photo\\'+'photo'+str(i)+'.jpg'
with open(filename,'w'):
urllib.request.urlretrieve(link,filename)
爬取结果